Moving Node-RED to a monorepo with multiple modules
21 Mar 2019How we tore apart the internals of Node-RED and glued it back together without users knowing
There are two logical parts of Node-RED; the runtime where flows run and the editor where flows are edited. Ever since the start of the project, these two parts have been bundled together in a single blob of npm module.
With the 0.20 release we’ve just published, the internals of Node-RED have now been
split apart into 6 separate npm modules, along with the original node-red module
that now has the task of pulling those modules back together so the user doesn’t
know what we’ve done.
This post describes how we went about doing that and some of the challenges we faced along the way. If you want to see it for yourself, the code is here.
This blog post was presented at LNUG in September 2019.
One-vs-Many repositories.
When I started looking at how to structure the code to support this approach, I had to decide whether to keep all the code in one repo or to split it into one repo per module.
Splitting it out would have made it clear what code belongs to each module and make it easier for new developers to follow the structure.
But it would also greatly increase the administrative burden; multiple repositories to manage, with multiple issue lists and the need to carefully co-ordinate pull-requests when a new feature spanned multiple modules.
Keeping the code in one place made the most sense. The question was then how to do that in practice.
Tooling
I looked around at other projects that maintain multiple modules in a single repository. There seemed to be a split between ones that chose to use established tooling, such as Lerna and those that rolled their own solution.
Not wanting to needlessly reinvent the wheel, I spent some time playing with Lerna.
Lerna is a tool that optimizes the workflow around managing multi-package repositories with git and npm.
The problem I found was Lerna has grown over time and does a lot. That isn’t necessarily a bad thing, but I found it hard to visualise how we’d migrate into using it. I got too caught up bouncing between the different options it provides without settling on one approach.
I also found this post from Nolan Lawson on why PouchDB moved away from Lerna that gave some hands-on perspective - albeit from a while ago now.
Ultimately I decided I wanted to understand the code structure and consequences of the split, rather than instant delegate that to the tooling. It wouldn’t preclude us from adopting Lerna in the future - but we’d be able to do that better informed.
Laying out the code
The existing code structure was already split between the node.js based runtime and the browser-based editor:
├── editor // All editor src and resources
├── nodes // The default core nodes
├── red // The node.js runtime code
└── test // All test material
The primary target for repackaging was all of the node.js code under the red
directory. The code was already reasonable well componentised under there, but it
wasn’t perfect. It was littered with require statements with relative paths
that made assumptions about where particular files were.
The main challenge was figuring out a code layout that would allow the require
statements to be updated to the new module structure, whilst still just working
when run in the development environment.
This is where I came across an approach linked to in Nolan’s post - the “Alle” model.
First a quick detour into how node does module loading. When you call require
with a relative path, node loads that file directly. For example, given a pair
of files in adjacent directories:
.
├── a
│ └── index.js
└── b
└── index.js
The code in a/index.js can use the following code to load b/index.js:
const moduleB = require("../b/index.js");
Now, lets say a and b are properly formed npm modules - so they include a
package.json file. Rather than require using a relative path, we want to require
using the name of the module:
const moduleB = require("b");
When you pass the name of a module to require, node will check the current
directory for a node_modules directory and look in there for a module with that
name. If it doesn’t find one, it then checks the parent directory for node_modules
and so on until it reaches the root of the filesystem.
We could take advantage of that in layout out the code - by adding a node_modules
directory in the structure:
.
└── node_modules
├── a
│ └── index.js
└── b
└── index.js
Now, when module a does require("b"), node will search up the directory structure
find the node_modules directory and then find module b in there.
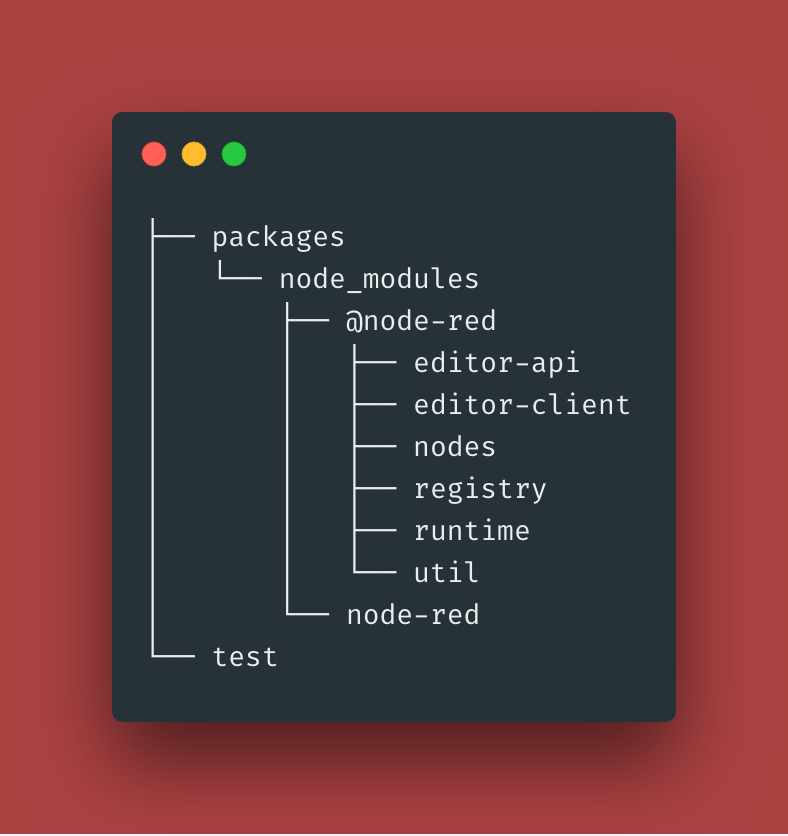
Putting this into practice led to a structure of:
├── packages
│ └── node_modules
│ ├── @node-red
│ │ ├── editor-api
│ │ ├── editor-client
│ │ ├── nodes
│ │ ├── registry
│ │ ├── runtime
│ │ └── util
│ └── node-red
└── test
├── editor
├── node_modules
│ └── nr-test-utils
├── nodes
└── unit
├── @node-red
│ ├── editor-api
│ ├── registry
│ ├── runtime
│ └── util
└── node-red
└── lib
You can see the seven new modules under packages/node_modules directory. They
can now require each other just as they will when properly installed with npm.
The test material was also restructured to match the layout. You may also spot
the same trick was used there to make a module called nr-test-utils available
to the test material.
This module provides two functions: require and resolve. They can be used by
the test material to require a particular file from the source tree without having
to hardcode the relative path from the test material tree into the source tree.
Getting GitHub to not ignore node_modules
One downside of this approach is that many IDEs are told to ignore node_modules
directories as they don’t typically contain code a developer is expected to edit.
Adding some rules to .gitignore to not ignore these directories seemed to fix it
for my preferred editor, atom.
node_modules
!packages/node_modules
!test/**/node_modules
We also found that GitHub would not generate diffs when showing changes to any files
under those directories, so we had to add .gitattributes file containing the following:
/packages/node_modules/** linguist-generated=false
That works on the desktop view, but the mobile view still suppresses diffs - not found a solution for that yet.
Managing dependencies
Each of the module directories has its own package.json listing its dependencies
as normal. There is also a package.json file at the top level of the project
that lists all dependencies (including development dependencies). This means
we don’t have to run npm install in each module directory - in fact, we actively
avoid doing that because those dependencies include references to our other modules
that npm won’t be able to install itself.
This does mean there is an overhead around managing the dependencies.
Any new dependency needs adding in two places; the top-level package.json file so it gets installed in the development environment and the module’s own package.json file so it gets installed when the published module is installed.
As soon as you have the same piece of information in two places, you raise the risk of them getting out of sync.
The ‘Alle’ method I linked to earlier talks about automating the generation of the individual package.json files - something we haven’t adopted.
Instead, to help manage this, a new script was added, scripts/verify-package-dependencies.js
that checks that every dependency listed in individual module package.json files
is also listed in the top-level package.json and that the version specifier matches.
The default set of tests now includes this check, so a build will fail if a mismatch
is found. The script can also be run with --fix to automatically update the versions
in the module package.json file to match the top level one.
The one scenario this doesn’t catch is when a new dependency is added to the top-level file, but not to the individual module. The unit tests will still pass because the module is installed at the top level - but the published module will be missing it. We’ll have to be careful around that until we plug the gap.
Managing versions
Another important design decision was how to manage the version numbers of the individual modules. For example, if a fix was needed in one module would we publish a new version of just that module, or would we bump the version of all the modules.
npm makes it easy to take either approach. If we wanted to be able to publish
modules individually, we could set the dependency version numbers to 0.20.x so
they would always get the latest version available in a given minor release.
The alternative would be to set them to a specific version to tie all the modules at
a particular level.
The problem with not keeping the versions closely aligned is what happens when a user hits a problem. The main goal of this entire refactoring was to hide the internal details of the split.
If a user hits a problem today, they can tell us what version of Node-RED they
have installed with a single number. It simply wouldn’t meet our goal if they
had to provide the versions of all seven modules so would know exactly what they
had installed. It would also be confusing to say they need to update their
install to get a fix but the node-red module version doesn’t change.
So for now we’re going to keep all the modules in sync.
To help with that task, another script was added, scripts/set-package-version.js
that can be used to update all of the individual package.json files with the
right version number.
Building a release
We already had a build task, grunt release, that took the source tree and built
the module that can be published to npm along with a zip file to upload to the
GitHub release.
That task has been updated to now build the 7 individual modules, this time packed as tgz files.
.dist
├── modules
│ ├── node-red-0.20.3.tgz
│ ├── node-red-editor-api-0.20.3.tgz
│ ├── node-red-editor-client-0.20.3.tgz
│ ├── node-red-nodes-0.20.3.tgz
│ ├── node-red-registry-0.20.3.tgz
│ ├── node-red-runtime-0.20.3.tgz
│ └── node-red-util-0.20.3.tgz
└── node-red-0.20.3.zip
Those tgz files can be published one at a time to npm - ensuring the node-red
module is done last. Currently that’s a manual task and something that is ripe
for automating in the future.
What next?
On reflection, having published the 0.20 release and a handful of subsequent maintenance releases, I’m pretty happy with the approach we took. Aside from a few more bits of task automation we could add, I think we have created a project structure that is well defined and easy to work with.
The main success has been that we did this without a single issue from a user related to the module structure or packaging. Users have no idea we made these changes - unless they read the release notes where we keep talking about it.